
Dear Readers,
In this article we will see Cassandra Data distribution and replication.

Cassandra is a Distributed NoSQL database means all the data is distributed across the Cluster. in Cassandra data distribution and replication go together.
The distribution and replication depending on the partition key, key value and Token range.
Cassandra Table:
A collection of ordered columns fetched by table row. A table consists of columns and has a primary key.
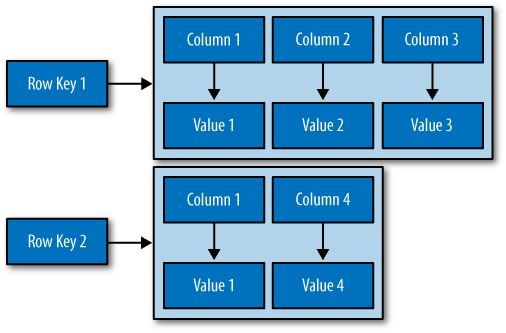
On the above diagram column1 having the Primary key
Primary key value is acting as the partition key. A Partitioner uses the hash functioning and determines Token range from partition key.
A Partitioner determines which node will receive the first replica of a piece of data, and how to distribute other replicas across other nodes in the cluster.
Refer this below link for more info.
https://www.ktexperts.com/key-components-in-cassandra/
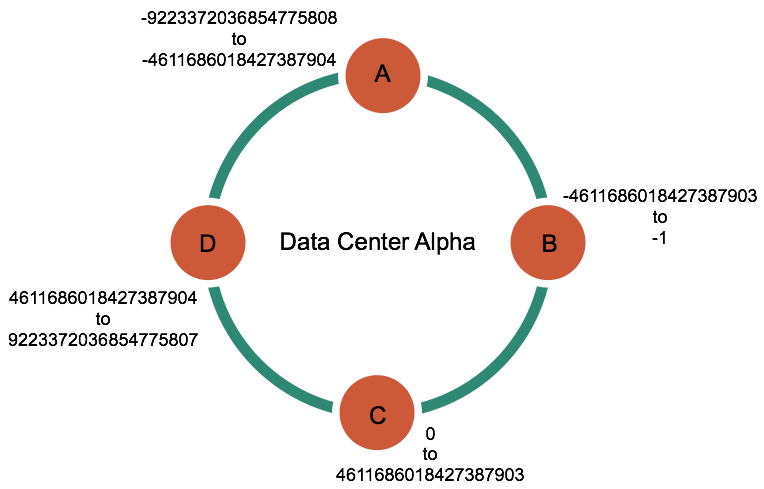
Consistent hashing:
A Partitioner uses the Consistent hashing, It allows distribution of data across a cluster.
The Consistent hashing minimizes reorganization of cluster when nodes are added or removed.
Cassandra uses the Murmur3hash function (default) for Consistent hashing. Each node in the cluster is responsible for a range of data based on the hash value.
In the below diagram you can see the distributed token range for 4 node cluster.
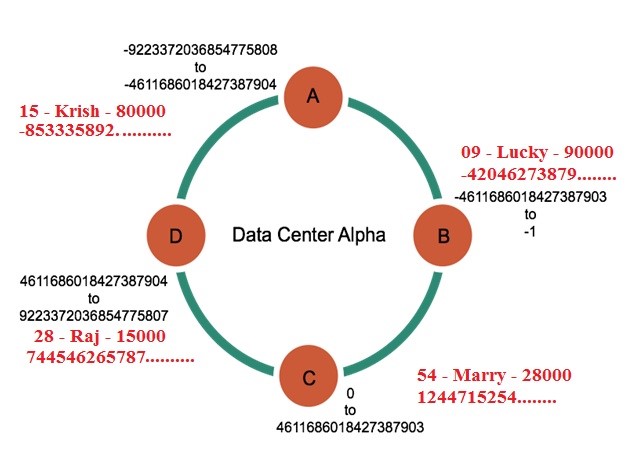
Example: A table with user details.
| USERID | NAME | SAL |
| 28 | Raj | 15000 |
| 15 | Krish | 80000 |
| 54 | marry | 28000 |
| 9 | Lucky | 90000 |
On the above diagram USERID having the Primary key. Hash values in a four node cluster.
Murmur3 Partitioner generates a hash value to each partition key.
| Partition key | Murmur3 hash value |
| Raj | 744546265787223821 |
| Krish | -853335892720368062 |
| Marry | 124471525403678548 |
| Lucky | -420462738791245812 |
Cassandra places the data on each node according to the value of the partition key and the range that the node is responsible for the data.
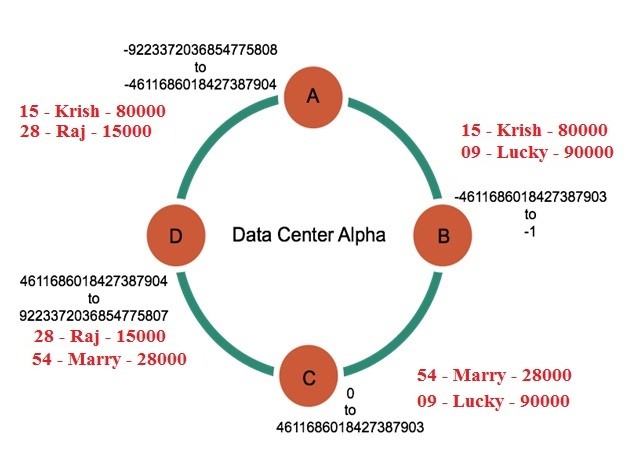
Replication factor:
Replication factor indicates the total number of replicas across the cluster.
Let’s tack Replication factor 2 for this 4 node cluster.
A replication factor of 2 means two copies of each row on the cluster where each copy is on a different node. In Cassandra All replicas are equally important there is no primary or master replica.
Thank you for giving your valuable time to read the above information. Please click here to subscribe for further updates
KTEXPERTS is always active on below social media platforms.
Facebook : https://www.facebook.com/ktexperts/
LinkedIn : https://www.linkedin.com/company/ktexperts/
Twitter : https://twitter.com/ktexpertsadmin
YouTube : https://www.youtube.com/c/ktexperts





sai
Informative and good explanation with diagrams.
Gayatri
Good Data