
RULES FOR DATA MODELLING IN CASSANDRA:

Cassandra is a query language which is resembles with SQL, but the modulation of data is completely different when compared with other data types.
In Cassandra, a worst model of data can lower the performance, especially when the data is tried to implement in RDBMS.
CASSANDRA DATA MODEL RULES:
In Cassandra the database is not supported by support joins, group by, OR clause, aggregations, etc. So, the data must be stored in a way that it should be retrievable. So, we must keep the rules in our mind while modelling the data in Cassandra.
Maximize the number of writes:
In Cassandra, writes are very cheap. Cassandra is optimized for high write performance. So, try to maximize your writes for better read performance and data availability. There is a tradeoff between data write and data read. So, optimize your data read performance by maximizing the number of data writes.
Maximize Data Duplication:
Data denormalization is a defect in Cassandra. memory is more expensive as compared to disk space. As Cassandra is a NOSQL database, duplication is provided instant data availability with reducing failures in the nodes.
Maintenance of Cluster:
The amount of data on each node is of Cassandra cluster. Data is spread to different nodes depended on the no. of partition keys available in Cassandra and the very first key is known for primary key. So, we must follow the primary key spreading data evenly around the cluster.
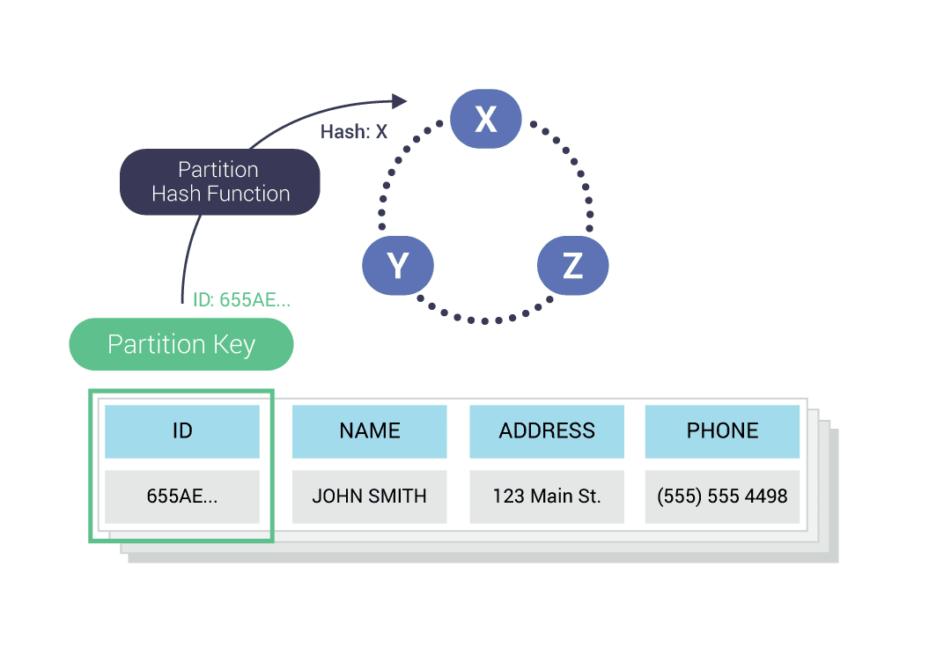
Good Primary Key in Cassandra:
Let’s take an example and find which primary key is good.
Here is an example of employee details.
Create table employee details.
(
ID , int
Name , text,
Joining year int
Salary double
Primary key (ID, name)
)

In the above example
👉 Id is the partition key.
👉 Name is clustering column.
👉Data will be clustered on the basis of employee name. only one partition key will create for each employee.
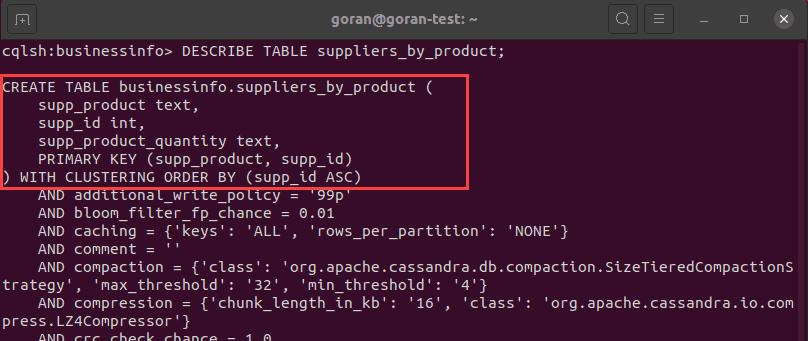
Create table according to your queries.
Create table according to your queries. Create a table that will satisfy your queries. Try to create a table in such a way that a minimum number of partitions needs to be read.
RELATIONSHIPS HANDLING:
One to one relationship or one to many relationships is Cassandra is deals with the correspondence between one-on-one table and one to multiple tables.
👉 ONE TO ONE: For example, the employee can register only one course, and I want to search on a employee that in which course a particular employee is registered in.
👉 ONE TO TWO: For example, a course can be studied by many employees. I want to search all the employees that are studying a particular course.
So, by querying on course name, I will have many names that will be studying a particular course.
Author : Neha Kasanagottu |
LinkedIn : https://www.linkedin.com/in/neha-kasanagottu-5b6802272
Thank you for giving your valuable time to read the above information. Please click here to subscribe for further updates.
KTExperts is always active on social media platforms.
Facebook : https://www.facebook.com/ktexperts/
LinkedIn : https://www.linkedin.com/company/ktexperts/
Twitter : https://twitter.com/ktexpertsadmin
YouTube : https://www.youtube.com/c/ktexperts
Instagram : https://www.instagram.com/knowledgesharingplatform
Note: Please test scripts in Non Prod before trying in Production.




