
WRITE PATHS IN CASSANDRA:

TERMINOLOGY OF APACHE CASSANDRA:
👉 Gossips
👉 Partitioners
👉 Snitchers
👉 SSTables
👉 Tombstones
👉 Compactions
Cassandra uses murmur3 partitioners and murmur3 algorithms to create Tokens.
Cassandra Data Write Path:
How Data Is Written:
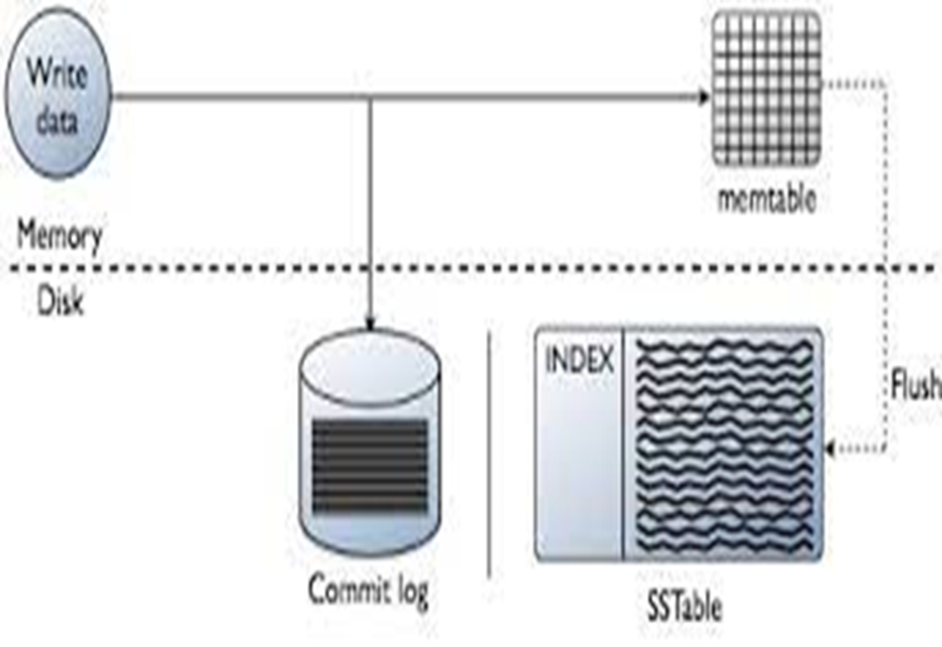
Data is processed by Cassandra at multiple points along the write path, commencing with the instantaneous logging of a write and concluding with a write to disc.
1. Logging data in the commit log
2. Writing data to the memtable
3. Flushing data from the memtable
4. Storing data on disk in SSTables
Logging Data In Commit Log:
When a write happens, Cassandra appends writes to the commit log on disc in addition to storing the data in a memory structure known as a memtable for adjustable durability. Every write that is done to a Cassandra node ends up in the commit log; these durable writes don’t disappear when a node loses power. Cassandra searches up data partitions by key in a write-back cache called the memtable. The memtable is flushed once it has stored writes in a sorted manner up to a specified maximum.
Flushing Data from The Memtable:
Cassandra writes the data in the memtable-sorted order to disc in order to flush the data. Additionally, a partition index mapping the tokens to a disc location is established on the disc. The memtable is placed in a queue that is flushed to disc when either the commit log space or the memtable content reach the configured threshold in megabytes. The memtable_heap_space_in_mb or memtable_offheap_space_in_mb setting in the cassandra. yaml file can be used to configure the queue. If there is more data to be flushed than memtable_cleanup_threshold . Writes are blocked by Cassandra until the next flush is successful. Node tool flush or node tool drain (which flushes memtables without listening for connections to other nodes) can be used to manually flush a table. It is advised as best practice to flush the memtable before restarting the nodes in order to minimize the commit log replay time. Replaying the commit log allows the writes that were present in the memtable prior to the node stopping to be restored in case it ceases functioning.
After matching data in the memtable is flushed to an SSTable on disc, data in the commit log is cleared.
Storing Data on Disc Sstables:
Each table has its own SSTables and Memtables. Tables can share the commit log. After the memtable has been flushed, SSTables cannot be changed. As such, a partition is usually spread across several SSTable files for storage. There are more SSTable structures available to help with read operations.
The SSTables are disk-based files. With Cassandra 2.2 and later, the naming standard for SSTable files was modified to shorten the file path. The data directory where the data files are kept differs depending on the installation. Every table is stored in a directory within the data directory for every key space.
Each table that Cassandra builds has its own subfolder, which enables you to symlink it to a desired physical drive or storage volume. This allows for better performance by moving highly active tables to faster media, such SSDs, and it also partitions tables across all attached storage devices for improved I/O balancing at the storage layer.
Author : Neha Kasanagottu |
LinkedIn : https://www.linkedin.com/in/neha-kasanagottu-5b6802272
Thank you for giving your valuable time to read the above information. Please click here to subscribe for further updates.
KTExperts is always active on social media platforms.
Facebook : https://www.facebook.com/ktexperts/
LinkedIn : https://www.linkedin.com/company/ktexperts/
Twitter : https://twitter.com/ktexpertsadmin
YouTube : https://www.youtube.com/c/ktexperts
Instagram : https://www.instagram.com/knowledgesharingplatform
Note: Please test scripts in Non Prod before trying in Production.




