Dear Readers,
In this article, we will see SQL Server Database Architecture.

SQL Server MDF Files
In the SQL Server Primary Data Files are the basic data files which are related to the database for the storing and supervision of the information.
MDF file in SQL Server are associated with other related files of the same database. That is why every database is represented by Primary Data File.
Therefore, all the triggers, stored procedures, views, tables etc. related to the same database are also stored in the MDF file.
On the other hand, we can say that the MDF file is the key element of database administration and data substances on the server.
These primary database files are denoted as .mdf, i.e. Master Database File.
SQL Server LDF Files
The LDF files in SQL Server are very useful for the database recovery purpose in future.
The limitations and size of LDF file can be defined at the time of database designing.
Every database has at least one log data file, but it is also possible that there may be several data log files for the same database.
SQL Server LDF files store the transaction information (insert, update, delete etc.)
Log files helps to track the changes in the database and helps in tracking the source of problems when any threat occurs.
Log files are also used for the database forensics purpose as they log the information regarding each activity conducted on the associated database.
The extension of log data file is .ldf.
Importance of MDF and LDF Files in SQL Server
The most important aspect of these files is that it can be used as backup files.
In SQL Server database sometimes errors occurs due to improper/unexpected shutdown of computer system, virus attack and many other reasons that create severe problem related to database access.
Reasons of SQL Server MDF and LDF Files
MDF and LDF files may corrupt due to some reasons. Some of them are like:
👉 Storage Size may prove to be an important aspect for turning MDF and LDF files as corrupted and damaged.
👉 Suspicious Mode of Computer is also an important reason in the corruption of database files.
👉 Modification of Database During DROP Operation may also be a reason of database file corruption.
👉 Hardware Issue is an important reason behind the data corruption. Thus, an administrator always keeps a check on the hardware regularly.
👉 Viruses or Bug Programs are also responsible for the MDF and LDF corruption on SQL Server database.
NDF file is a secondary data files. You can only have one primary data file for a database. The rest made up by secondary data files.
But it’s not necessary to have a secondary data file. Therefore, some databases may not have any secondary data file. But it’s also possible to have multiple secondary data files for a single database.
In an era of computing, MDF can be expanded as “Master Database file”.
Database is a collection of tables that is used for data storage.
These files are extremely important as without Master database you cannot run the SQL Server.
This file is used to store system level information for running server configuration and records the presence of all the existing database along with their location and records any installation for the server.
Microsoft SQL Server supports different kinds of data types such as Integer, Char, Float, Decimal, Varchar, Binary, Text etc. The primary data present in database are stored in.mdf and .ndf file allows the data in a database to be used across the other files whereas .ldf is generally used to store log files.
Every database contains one primary database file and one or more secondary database file.
Primary Data File consists of the initial information and refers to information in another file. The most commonly used extension for this data file is .mdf.
Secondary Data Files are optional files and are generated by users which can be created and deleted at user’s will.
You must always create a backup of the master database because if the master files get corrupted, it can be restored by the backup created.
Sometimes when the database is corrupted SQL Server cannot be started at all. These files also have a compact version in Windows Phone popularly known as SQL Server Compact (.sdf) files which are used for storing small amount of data and are also used in website.
But it showcase a poor performance whereas when you use these MDF files it provides an advantage of using bigger sites and helps in storing a lot of data and needs to be installed on the server.
Why Secondary Database Files (NDF) Created
Whenever the data limit exceeds in a single file, secondary files can be generated.
They are generally created to disperse data across multiple disks such that it can handle the fault tolerance and helps the database to grow. The extension file commonly used is .ndf.
Since it is difficult to manage large files we can distribute files to reduce the load on IO Systems.
Secondary database files help in easy access to data multiple threads and increasing the overall IO performance. You cannot open the NDF file without attaching the corresponding MDF file to it.
Second important reason is Disaster Recovery.
During disaster, when there is urgency to access current data, recovery of entire data might take huge amount of time.
sing secondary files allows you to recover the primary data and access these queries while the secondary data are being loaded from the warehouses.
For example if a you need to recover the entire database but only requires access to the most recent data ,then the historical data can be recovered slowly while users can still work on the recent data.
Transaction Log Logical Architecture
The SQL Server transaction log operates logically as if the transaction log is a string of log records.
Each log record is identified by a log sequence number (LSN). Each new log record is written to the logical end of the log with an LSN that is higher than the LSN of the record before it.
Log records are stored in a serial sequence as they are created such that if LSN2 is greater than LSN1, the change described by the log record referred to by LSN2 occurred after the change described by the log record LSN1.
Each log record contains the ID of the transaction that it belongs to.
For each transaction, all log records associated with the transaction are individually linked in a chain using backward pointers that speed the rollback of the transaction.
Transaction Log Physical Architecture
The transaction log in a database maps over one or more physical files. Conceptually, the log file is a string of log records.
Physically, the sequence of log records is stored efficiently in the set of physical files that implement the transaction log.
There must be at least one log file for each database.
The SQL Server Database Engine divides each physical log file internally into a number of virtual log files (VLFs).
Virtual log files have no fixed size, and there is no fixed number of virtual log files for a physical log file.
The Database Engine chooses the size of the virtual log files dynamically while it is creating or extending log files.
The Database Engine tries to maintain a small number of virtual files. The size of the virtual files after a log file has been extended is the sum of the size of the existing log and the size of the new file increment.
The size or number of virtual log files cannot be configured or set by administrators.
Virtual log file (VLF) creation follows this method:
👉 If the next growth is less than 1/8 of current log physical size, then create 1 VLF that covers the growth size (Starting with SQL Server 2014 (12.x))
👉 If the next growth is more than 1/8 of the current log size, then use the pre-2014 method:
👉 If growth is less than 64MB, create 4 VLFs that cover the growth size (e.g. for 1 MB growth, create four 256KB VLFs)
👉 If growth is from 64MB up to 1GB, create 8 VLFs that cover the growth size (e.g. for 512MB growth, create eight 64MB VLFs)
👉 If growth is larger than 1GB, create 16 VLFs that cover the growth size (e.g. for 8 GB growth, create sixteen 512MB VLFs)
If the log files grow to a large size in many small increments, they will have many virtual log files. This can slow down database startup and also log backup and restore operations.
Conversely, if the log files are set to a large size with few or just one increment, they will have few very large virtual log files.
For more information on properly estimating the required size and auto grow setting of a transaction log, refer to the Recommendations section of Manage the size of the transaction log file.
We recommend that you assign log files a size value close to the final size required, using the required increments to achieve optimal VLF distribution, and also have a relatively large growth_increment value.
The transaction log is a wrap-around file. For example, consider a database with one physical log file divided into four VLFs.
When the database is created, the logical log file begins at the start of the physical log file.
New log records are added at the end of the logical log and expand toward the end of the physical log.
Log truncation frees any virtual logs whose records all appear in front of the minimum recovery log sequence number (MinLSN).
The MinLSN is the log sequence number of the oldest log record that is required for a successful database-wide rollback.
The transaction log in the example database would look similar to the one in the following illustration.
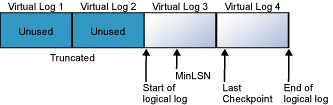
When the end of the logical log reaches the end of the physical log file, the new log records wrap around to the start of the physical log file.
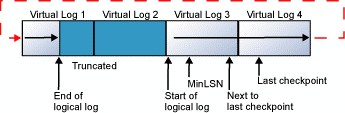
This cycle repeats endlessly, as long as the end of the logical log never reaches the beginning of the logical log.
If the old log records are truncated frequently enough to always leave sufficient room for all the new log records created through the next checkpoint, the log never fills.
However, if the end of the logical log does reach the start of the logical log, one of two things occurs:
👉 If the FILEGROWTH setting is enabled for the log and space is available on the disk, the file is extended by the amount specified in the growth increment parameter and the new log records are added to the extension.
👉 For more information about the FILEGROWTH setting, see ALTER DATABASE File and File group Options (Transact-SQL).
👉 If the FILEGROWTH setting is not enabled, or the disk that is holding the log file has less free space than the amount specified in growth increment, an 9002 error is generated.
👉 Refer to Troubleshoot a Full Transaction Log for more information.
If the log contains multiple physical log files, the logical log will move through all the physical log files before it wraps back to the start of the first physical log file.
Log Truncation
Log truncation is essential to keep the log from filling.
Log truncation deletes inactive virtual log files from the logical transaction log of a SQL Server database, freeing space in the logical log for reuse by the physical transaction log.
If a transaction log were never truncated, it would eventually fill all the disk space that is allocated to its physical log files.
Before the log can be truncated, a checkpoint operation must occur.
A checkpoint writes the current in-memory modified pages (known as dirty pages) and transaction log information from memory to disk.
When the checkpoint is performed, the inactive portion of the transaction log is marked as reusable.
Thereafter, the inactive portion can be freed by log truncation.
The following illustrations have shown a transaction log before and after truncation.
The first illustration shows a transaction log that has never been truncated. Currently, four virtual log files are in use by the logical log.
The logical log starts at the front of the first virtual log file and ends at virtual log 4.
The MinLSN record is in virtual log 3.
Virtual log 1 and virtual log 2 contain only inactive log records.
These records can be truncated. Virtual log 5 is still unused and is not part of the current logical log.
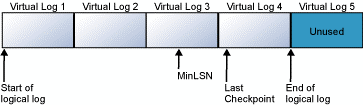
Virtual log 1 and virtual log 2 have been freed for reuse.
The logical log now starts at the beginning of virtual log 3.
Virtual log 5 is still unused, and it is not part of the current logical log.
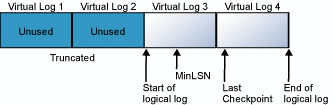
Log truncation occurs automatically after the following events, except when delayed for some reason:
👉 Under the simple recovery model, after a checkpoint.
👉 Under the full recovery model or bulk-logged recovery model, after a log backup, if a checkpoint has occurred since the previous backup.
Recovery model:
There are THREE different recovery models of SQL Server, you should select SQL Server recovery model to manage log files and prepare for the SQL recovery in case of disaster. This document is to talk about three SQL Server recovery models: simple, full and bulk-logged. Among all, you should back up your SQL Server database.
Simple Recovery Model
👉 When you choose the simple recovery model, SQL Server maintains only a minimal amount of information in the transaction log. SQL Server truncates the transaction log each time the database reaches a transaction checkpoint, leaving no log entries for disaster recovery purposes.
👉 In databases using the simple recovery model, you may restore full or differential backups only.
👉 It is not possible to restore such a database to a given point in time, you may only restore it to the exact time when a full or differential backup occurred.
👉 Therefore, you will automatically lose any data modifications made between the time of the most recent full/differential backup and the time of the failure.
👉 Simple Recovery requires the least administration. It is easier to manage than the Full or Bulk-Logged models, but at the expense of higher data loss exposure if a data file is damaged. Simple Recovery is not an appropriate choice for production systems where loss of recent changes is unacceptable. When using Simple Recovery, the backup interval should be long enough to keep the backup overhead from affecting production work, yet short enough to prevent the loss of significant amounts of data.
👉 Advantage: permits high-performance bulk copy operations. Reclaims log space to keep space requirements small.
👉 Disadvantage: changes since the most recent database or differential backup must be redone.
Full Recovery Model
SQL Server preserves the transaction log until you back it up.
This allows you to design a disaster recovery plan that includes a combination of full and differential database backups in conjunction with transaction log backups.
You have the most flexibility restoring databases using the full recovery model when a database failure happens.
In addition to preserving data modifications stored in the transaction log, the full recovery model allows you to restore a database to a specific point in time.
Advantage: no work is lost due to a lost or damaged data file. It can recover to an arbitrary point in time.
Disadvantage: if the log is damaged, changes since the most recent log backup must be redone.
👉 Disadvantage: changes since the most recent database or differential backup must be redone.
Full Recovery Model
SQL Server preserves the transaction log until you back it up.
This allows you to design a disaster recovery plan that includes a combination of full and differential database backups in conjunction with transaction log backups.
You have the most flexibility restoring databases using the full recovery model when a database failure happens.
In addition to preserving data modifications stored in the transaction log, the full recovery model allows you to restore a database to a specific point in time.
Advantage: no work is lost due to a lost or damaged data file. It can recover to an arbitrary point in time.
Disadvantage: if the log is damaged, changes since the most recent log backup must be redone.
Bulk-logged Recovery Model
The bulk-logged recovery model is a special-purpose model that works in a similar manner to the full recovery model.
The only difference is in the way it handles bulk data modification operations. The bulk-logged model records these operations in the transaction log using a technique known as minimal logging. This saves significantly on processing time but prevents you from using the point-in-time restore option.
Advantage: permits high-performance bulk copy operations, minimal log space is used by bulk operations.
Disadvantage: if the log is damaged, or bulk operations occurred since the most recent log backup, changes since that last backup must be redone.
Full Recovery and Bulk-Logged Recovery models provide the greatest protection for data.
These models rely on the transaction log to provide full recoverability and to prevent work loss in the broadest range of failure scenarios.
The Bulk-Logged model provides higher performance and lower log space consumption for certain large-scale operations.
Thank you for giving your valuable time to read the above information. Please click here to subscribe for further updates
KTEXPERTS is always active on below social media platforms.
Facebook : https://www.facebook.com/ktexperts/
LinkedIn : https://www.linkedin.com/company/ktexperts/
Twitter : https://twitter.com/ktexpertsadmin
YouTube : https://www.youtube.com/c/ktexperts
Instagram : https://www.instagram.com/knowledgesharingplatform